Tonight my wife came to me with the problem of Dollar Words. The idea is that you can assign a numerical value to each letter of the alphabet (a = 1, b = 2 … z = 26). If you replace each letter of a word with the value and add the values up, you get a sum. If the sum adds up to 100, that’s called a dollar word. There are many lists of dollar words on the internet, but the challenge my wife presented was to come up with as many 85 cent words as I could. I tried for a few minutes but was not able to find any! Of course, this called for a brute force attack.
I remembered some time ago looking at natural language processing to break a “corpus” of text up into “tokens”, or smaller units of text. These units could be single words. Each word could then be calculated and then I could figure out which ones were 85 cents.
I used the Tidy Text Mining with R example to come up with a corpus of words. The example they use is all the words in Jane Austen’s published works, which is a little dated, but sufficient.
library(tidytext)
library(janeaustenr)
library(dplyr)##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionlibrary(stringr)
library(ggplot2)First, some helper functions:
# converts a letter into its value, such as a to 1, z to 26
letterToInt <- function(x) {
which(letters == x)
}
# determines if a word has non-letters such as punctuation or numbers
hasNonLetters <- function(x) {
str_detect(x, "\\W|[[:digit:]]|[[:punct:]]")
}
# calculates the dollar value of a word
valueCalculate <- function(x) {
x <- tolower(x) # makes word all lowercase
wordsplit <- strsplit(x, split = "") # splits word into letters
sum(sapply(unlist(wordsplit), letterToInt)) # calculates word value
}Then I loaded the Jane Austen corpus and made them into a list of words. This is copied entirely from the Tidy Text Mining web site.
original_books <- austen_books() %>%
group_by(book) %>%
mutate(linenumber = row_number(),
chapter = cumsum(str_detect(text,
regex("^chapter [\\divxlc]",
ignore_case = TRUE)))) %>%
ungroup()
tidy_books <- original_books %>%
unnest_tokens(word, text)This results in a list of 725,055 tokens such as:
head(tidy_books)## # A tibble: 6 x 4
## book linenumber chapter word
## <fct> <int> <int> <chr>
## 1 Sense & Sensibility 1 0 sense
## 2 Sense & Sensibility 1 0 and
## 3 Sense & Sensibility 1 0 sensibility
## 4 Sense & Sensibility 3 0 by
## 5 Sense & Sensibility 3 0 jane
## 6 Sense & Sensibility 3 0 austenLooking just at the words, there were only 14,520 unique words, or tokens.
wordsall <- unique(tidy_books$word)
length(wordsall)## [1] 14520Here’s the calculation heavy step, getting rid of all the words that have letters or punctuation. I suppose I could have just removed all the letters or punctuations from words instead…
wordsall <- wordsall[!sapply(wordsall, hasNonLetters)]After this, all I had to do was calculate the values of the words that were left, and come up with a list of the ones that were equal to 85 cents.
wordsall <- sapply(wordsall, valueCalculate)
words85 <- which(wordsall == 85)
sort(labels(words85))## [1] "actress" "admirably" "advising" "affluent" "aggrandise"
## [6] "attainable" "awakening" "believing" "belonging" "blister"
## [11] "blundered" "bottom" "bracelets" "british" "burning"
## [16] "catalogue" "censure" "chaperone" "cherries" "circular"
## [21] "compelled" "confines" "contained" "convince" "creation"
## [26] "deceitful" "decrying" "dejection" "deliberated" "desiring"
## [31] "despatched" "devolve" "disregard" "dixons" "donwell"
## [36] "dormant" "dramatis" "eltons" "endurance" "enrolled"
## [41] "entitle" "espalier" "events" "excites" "falsehood"
## [46] "faulty" "fearless" "ferrars" "figures" "fitting"
## [51] "fixedly" "floors" "formidable" "forward" "fricassee"
## [56] "glories" "gossip" "grandmamma" "grieves" "hawkins"
## [61] "hedgerow" "heightened" "hollow" "humming" "impeaching"
## [66] "inaction" "inclines" "incurable" "indelicacy" "instance"
## [71] "intends" "kitty" "lengthen" "lengths" "library"
## [76] "lively" "maddoxes" "mansion" "memento" "mingling"
## [81] "moderated" "nought" "objecting" "obtrude" "oddities"
## [86] "original" "others" "palpably" "parting" "passing"
## [91] "patient" "pattened" "peculiar" "pelisse" "pembroke"
## [96] "poachers" "presence" "proceeds" "rapidly" "reciting"
## [101] "reckons" "remarks" "remnant" "replacing" "repute"
## [106] "residing" "resumed" "retract" "revived" "ridiculed"
## [111] "rubbers" "sagacity" "sensible" "sentence" "separate"
## [116] "settled" "shameful" "shewing" "silver" "sprigged"
## [121] "starve" "stealth" "steeles" "stepped" "stirs"
## [126] "stolen" "stoop" "storm" "streamed" "styled"
## [131] "swears" "thereon" "tilney" "tiptoe" "titles"
## [136] "tupman" "unaffected" "uneasy" "unfeigned" "unlocked"
## [141] "urgent" "vacation" "vaulted" "violence" "waiving"
## [146] "watching" "weddings" "wildly" "wright" "xlviii"
## [151] "yielding"The result consisted of 151 words reflecting the beauty of Austen’s writing. What a fun exercise!
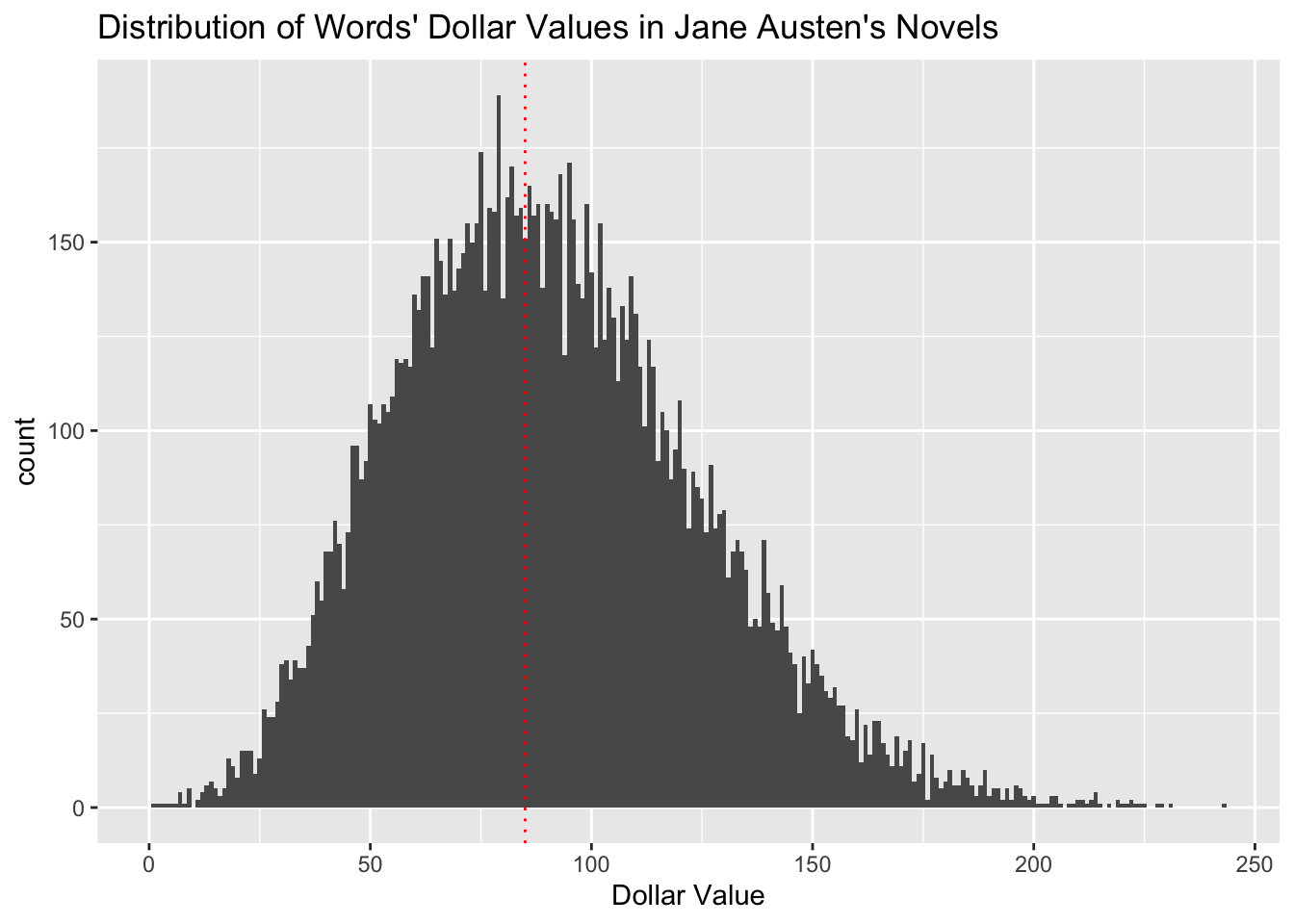
Before I go to bed, here’s the distribution of dollar values of words in Austen’s writing with the dotted red line at 85:
ggplot(as_tibble(wordsall), aes(x = value)) +
geom_histogram(binwidth = 1) +
xlab("Dollar Value") +
ggtitle("Distribution of Words' Dollar Values in Jane Austen's Novels") +
geom_vline(xintercept = 85, linetype = "dotted", color = "red")